
RAG란 무엇일까요? AI가 답하기 전에 관련 자료를 먼저 검색해 ‘오픈북 시험’처럼 근거를 보고 답하게 만드는 기술입니다. 환각을 줄이고 최신 정보와 내 문서를 반영하는 RAG의 원리와 쓰임을 처음 보는 분도 이해하도록 풀었습니다.
RAG, 한마디로 ‘AI의 오픈북 시험’
ChatGPT에 뭔가 물었더니 그럴듯하지만 틀린 답을, 그것도 자신 있게 내놓아 당황한 적 있으신가요? 이걸 ‘환각(hallucination)’이라고 합니다. RAG(검색증강생성, Retrieval-Augmented Generation)는 바로 이 문제를 줄이는 기술입니다.
핵심은 간단합니다. AI가 머릿속 기억만으로 답하는 ‘폐쇄형 시험’ 대신, 답하기 직전에 관련 자료를 검색해 손에 쥐고 답하는 ‘오픈북 시험’으로 바꾸는 것입니다. 그래서 모델을 다시 학습시키지 않고도 최신 정보나 내 회사 문서에 근거한 답을 만들 수 있습니다.
왜 RAG가 필요한가 — LLM의 세 가지 한계
RAG는 거대 언어모델(LLM)이 가진 빈틈을 메우려고 나왔습니다.
- 지식이 학습 시점에 멈춰 있다: 모델은 훈련받은 시점까지만 압니다. 그 이후 소식이나 어제 올린 사내 문서는 모릅니다.
- 모르면 지어낸다(환각): 빈칸을 만나면 ‘모른다’가 아니라 그럴듯한 말을 만들어 채웁니다.
- 내 데이터를 모른다: 우리 회사 규정, 내 노트는 학습에 들어 있지 않습니다.
RAG는 ‘검색’이라는 단계를 끼워 넣어 이 세 가지를 한 번에 보완합니다. 필요한 자료를 그때그때 찾아 근거로 주니, 최신성·정확성·개인화가 동시에 올라갑니다.
RAG는 어떻게 동작하나 — 4단계
RAG의 영어 이름에 동작 순서가 그대로 들어 있습니다. 검색(Retrieval) → 보강(Augmented) → 생성(Generation). 실제로는 준비 단계까지 4단계로 움직입니다.
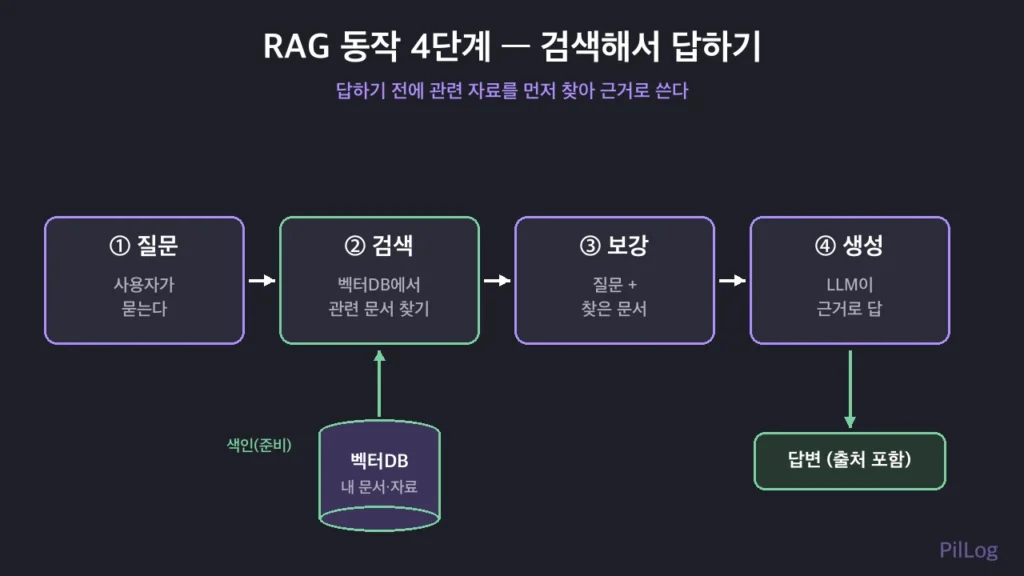
- 색인(준비): 문서를 잘게 쪼개 의미를 숫자(벡터)로 바꾼 뒤 ‘벡터DB’라는 검색용 창고에 저장합니다. 이 숫자 변환을 ‘임베딩’이라고 합니다.
- 검색: 사용자의 질문도 숫자로 바꿔, 의미가 가장 가까운 문서 조각을 창고에서 찾아냅니다.
- 보강: 찾아온 조각을 질문과 함께 묶어 AI에게 전달합니다.
- 생성: AI가 그 근거를 바탕으로 답을 씁니다. 이상적으로는 출처까지 함께 보여줍니다.
여기서 가장 중요한 건 2번 검색입니다. 엉뚱한 자료를 찾아오면 아무리 똑똑한 모델도 엉뚱하게 답합니다. RAG의 품질은 ‘생성’보다 ‘무엇을 찾아오느냐’에서 갈린다고 할 만큼 검색 단계가 핵심입니다.
RAG vs 파인튜닝 — ‘오픈북’과 ‘재수강’의 차이
RAG와 자주 헷갈리는 게 ‘파인튜닝’입니다. 둘 다 AI를 내 입맛에 맞추지만 방향이 다릅니다.
| 구분 | RAG (오픈북 시험) | 파인튜닝 (재수강) |
|---|---|---|
| 바꾸는 것 | 입력(자료를 검색해 넣음) | 모델 자체(다시 학습) |
| 잘하는 일 | 최신·사실 지식 주입, 출처 추적 | 말투·형식·도메인 스타일 체화 |
| 지식 갱신 | 문서만 교체(즉시) | 다시 학습(느리고 비쌈) |
| 비용 | 낮음 | 중~높음 |
쉽게 말해 “무엇을 아는가”를 바꾸려면 RAG, “어떻게 말하는가”를 바꾸려면 파인튜닝입니다. 최신 정보나 내 문서를 답에 반영하는 대부분의 경우는 RAG가 더 싸고 빠릅니다.
RAG는 어디에 쓰이나
이미 우리가 쓰는 도구 곳곳에 RAG가 들어 있습니다.
- AI 챗봇·프로젝트 기능: 파일을 잔뜩 올리면 전부 읽는 대신 질문과 관련된 부분만 검색해 답합니다.
- 사내 지식 챗봇: 회사 규정·매뉴얼을 벡터DB에 넣어 두고 직원 질문에 근거 있게 답합니다.
- 개인 문서 질의응답: 내 노트·PDF를 로컬에 두고 “그 자료에서 이거 찾아줘”처럼 씁니다.
마무리 — RAG는 ‘검색을 잘해야’ 빛난다
RAG는 AI를 더 똑똑하게 만드는 마법이 아니라, 좋은 근거를 잘 찾아다 주는 비서에 가깝습니다. 직접 클로드 프로젝트와 로컬 문서로 써보면, 같은 모델이라도 자료를 잘 정리해 넣었을 때와 아무 문서나 욱여넣었을 때의 답 품질 차이가 분명합니다. 그래서 RAG를 도입할 때 진짜 승부처는 모델 선택이 아니라 문서를 어떻게 쪼개고 검색하느냐입니다.
자주 묻는 질문
Q. RAG를 쓰면 AI가 거짓말(환각)을 아예 안 하나요?
크게 줄지만 0이 되지는 않습니다. 근거 문서를 줘도 모델이 그 내용을 무시하거나 과장해 해석할 수 있습니다. 그래서 출처를 함께 표기하게 하고, 중요한 답은 사람이 근거 문서와 대조해 확인하는 습관이 필요합니다.
Q. 문서가 아주 많으면 그냥 통째로 AI에 넣으면 안 되나요?
한 번에 넣을 수 있는 양(컨텍스트)에 한계가 있고, 무관한 내용까지 넣으면 오히려 답 품질이 떨어집니다. RAG는 전부 넣는 대신 질문과 관련된 조각만 골라 넣어 비용과 정확도를 동시에 챙기는 방식입니다.





