
양자화란 무엇일까요? 수십억 매개변수짜리 AI 모델을 4비트로 압축해 노트북·스마트폰에서도 돌아가게 만드는 기술입니다. 사진을 적당히 압축하듯 모델을 줄이는 원리와 Q4·Q8 차이, 로컬 LLM 활용까지 처음 보는 분도 이해하도록 풀었습니다.
수십억짜리 모델이 어떻게 노트북에서 돌까
거대한 AI 모델은 보통 고가의 서버 GPU에서 돕니다. 그런데 요즘은 같은 모델을 일반 노트북, 심지어 스마트폰에서도 돌립니다. 어떻게 가능할까요? 답이 바로 양자화(quantization)입니다.
양자화란, AI 모델이 쓰는 숫자의 정밀도를 낮춰 모델의 용량과 메모리 사용량을 확 줄이는 기술입니다. 고화질 사진(RAW)을 적당한 JPG로 압축하면 파일 크기는 1/4로 줄어도 눈으로는 거의 차이가 없는 것과 같습니다. 모델을 이렇게 ‘압축’하면 작은 기기에서도 돌릴 수 있게 됩니다.
정밀도를 낮춘다는 게 무슨 뜻일까
AI 모델은 수많은 ‘가중치(weight)’라는 숫자로 이루어져 있습니다. 원래 이 숫자들은 16비트 실수(FP16)처럼 정밀하게 저장됩니다.
양자화는 이 숫자를 8비트(INT8)나 4비트(INT4) 같은 더 거친 단위로 바꿉니다. 소수점 아래를 잘라내 표현을 단순하게 만드는 셈입니다. 숫자 하나하나가 차지하는 자리가 줄어드니, 모델 전체 용량과 메모리(VRAM)도 함께 줄어듭니다. 대신 약간의 정확도를 내주는 거래입니다.
어디까지 줄일 수 있나 — 비트 단계의 저울
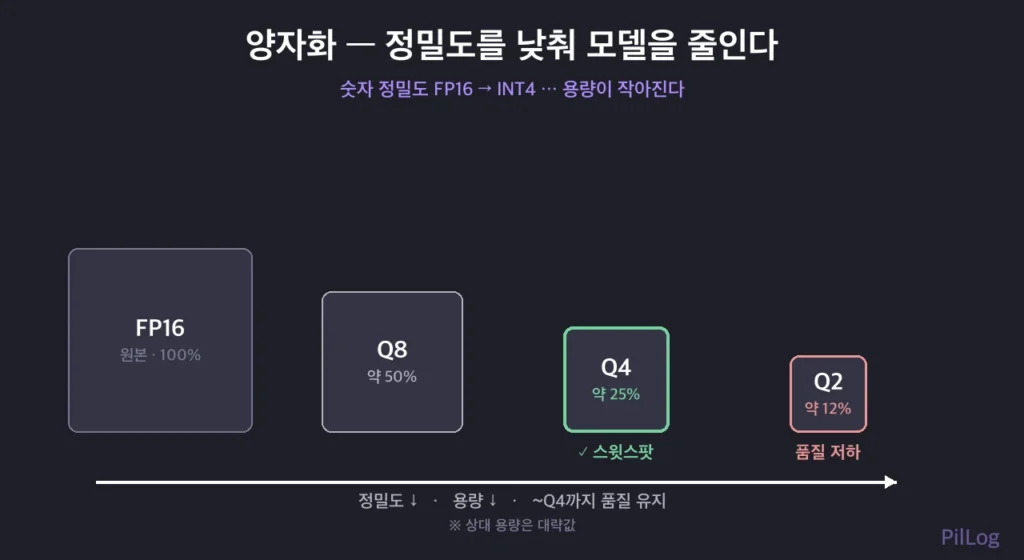
정밀도는 한 단계씩 낮출 수 있고, 낮출수록 가벼워지지만 품질도 조금씩 떨어집니다. 상대 용량은 대략 이런 식입니다.
| 정밀도 | 상대 용량(대략) | 품질 | 쓰임 |
|---|---|---|---|
| FP16(원본) | 100% | 최고 | 학습·고정밀 추론 |
| Q8(8비트) | 약 50% | 거의 원본 | 품질 우선 로컬 |
| Q4(4비트) | 약 25% | 체감 차이 작음 | 가장 흔한 선택 |
| Q2(2비트) | 약 12% | 저하 뚜렷 | 극한 저사양·실험 |
실전 감각은 분명합니다. 대개 4비트(Q4)가 ‘용량 1/4 + 품질 거의 유지’의 스윗스팟입니다. 더 줄이면(Q2) 가벼워지지만 답이 눈에 띄게 엉성해지기 시작합니다. 직접 노트북에서 Q4 모델을 돌려보면, 원본 대비 용량이 확 줄었는데도 일상적인 요약·번역 품질은 크게 다르지 않다는 걸 체감합니다.
PTQ vs QAT — 언제 압축하나
압축 시점에 따라 두 가지로 나뉩니다.
- PTQ(사후 양자화): 학습이 끝난 모델을 나중에 압축합니다. 간단하고 빠르지만 품질 손실이 생길 수 있습니다.
- QAT(양자화 인지 학습): 훈련 단계에서 미리 압축을 시뮬레이션합니다. 그만큼 압축 후에도 품질 손실이 작습니다.
요즘 일부 모델은 QAT로 만든 가중치를 따로 제공해, 압축해도 품질이 잘 유지되도록 돕습니다.
GGUF? Q4_K_M? — 다운로드할 때 보이는 이름들
로컬 LLM을 받아보면 파일 이름에 GGUF, Q4, Q8 같은 표시가 붙어 있습니다. 당황할 필요 없습니다.
- GGUF: 개인용 도구(예: Ollama, LM Studio)에서 쓰는 대표 배포 포맷입니다.
- Q4·Q8: 위에서 본 양자화 레벨입니다. 숫자가 작을수록 더 압축됐다는 뜻입니다.
- GPTQ·AWQ: 주로 서버·고성능 GPU용 양자화 방식입니다.
입문자라면 GGUF의 Q4부터 받아 써보고, 품질이 아쉬우면 Q8로 올리는 순서를 추천합니다.
마무리 — 양자화는 ‘줄이기’, 파인튜닝은 ‘바꾸기’
양자화는 모델을 똑똑하게 만드는 게 아니라, 능력은 최대한 지키면서 크기만 줄이는 기술입니다. 그래서 내 기기에서 AI를 돌리는 첫 관문이 바로 양자화 이해입니다. 비슷해 보이는 파인튜닝과는 목적이 다릅니다. 양자화는 모델을 ‘줄이고’, 파인튜닝은 모델을 ‘바꿉니다’. 내 PC에서 LLM을 처음 돌린다면, 너무 고민 말고 Q4 GGUF부터 시작해 보세요.
자주 묻는 질문
Q. 양자화하면 AI가 멍청해지나요?
4비트(Q4) 수준까지는 체감 품질 저하가 크지 않은 경우가 많습니다. 다만 2비트처럼 과하게 줄이면 답의 정확도와 일관성이 눈에 띄게 떨어집니다. ‘얼마나 줄이느냐’가 핵심이라, 보통 Q4를 기본값으로 두고 필요할 때 Q8로 올립니다.
Q. 양자화와 파인튜닝은 같이 쓸 수 있나요?
네, 둘은 별개의 작업이라 함께 쓸 수 있습니다. 파인튜닝으로 모델의 말투·전문성을 바꾼 뒤, 그 모델을 양자화해 작은 기기에서 돌리는 식입니다. 줄이기(양자화)와 바꾸기(파인튜닝)는 목적이 달라 서로를 방해하지 않습니다.





